Document Actions
CVMP 2009
Cosine Lobe Based Relighting from Gradient Illumination Photographs
extended and revised for JVRB
urn:nbn:de:0009-6-32649
Abstract
We present an image-based method for relighting a scene by analytically fitting cosine lobes to the reflectance function at each pixel, based on gradient illumination photographs. Realistic relighting results for many materials are obtained using a single per-pixel cosine lobe obtained from just two color photographs: one under uniform white illumination and the other under colored gradient illumination. For materials with wavelength-dependent scattering, a better fit can be obtained using independent cosine lobes for the red, green, and blue channels, obtained from three achromatic gradient illumination conditions instead of the colored gradient condition. We explore two cosine lobe reflectance functions, both of which allow an analytic fit to the gradient conditions. One is non-zero over half the sphere of lighting directions, which works well for diffuse and specular materials, but fails for materials with broader scattering such as fur. The other is non-zero everywhere, which works well for broadly scattering materials and still produces visually plausible results for diffuse and specular materials. We also perform an approximate diffuse/specular separation of the reflectance, and estimate scene geometry from the recovered photometric normals to produce hard shadows cast by the geometry, while still reconstructing the input photographs exactly.
Keywords: Lighting, Photographs, Gradient Illumination, Scene Geometry, Shadows, Relighting
Subjects: Lighting, Image Processing, Photography, Shadow
Image-based relighting is a powerful technique for synthesizing images of a scene under novel illumination conditions, based on a set of input photographs. In its most basic form, images of a scene are acquired [ Hae92 ] or rendered [ NSD94 ] under a set of basis lighting conditions. Then, a relit version of the scene can be produced by taking linear combinations of the basis lighting conditions, akin to compositing together different lighting passes of a model miniature. Debevec et al. [ DHT00 ] used a light stage device to acquire a dataset of a human face lit by a dense set of over two thousand lighting directions on the sphere, and showed that such datasets could be efficiently illuminated under novel real-world lighting conditions such as high dynamic range lighting environments through image-based relighting. Recent work in the area of precomputed radiance transfer [ SKS02 ], [ RH02 ], [ WTL05 ] has shown that pre-rendering an object's reflectance under basis illumination conditions can allow for real-time relighting as it moves through interactive environments. Basis illumination datasets have also been shown to be very useful for object recognition [ Ram06 ], including for faces.
The principal benefit to image-based relighting techniques is that complex illumination effects including spatially-varying diffuse and specular reflection, self-shadowing, mutual illumination, and subsurface scattering are all encoded within the data and thus appear accurately in the renderings, whereas traditional techniques would require far more advanced reflectometry and light transport simulation. The principal drawbacks are that a lot of data must be acquired and stored. This makes the techniques less practical for capturing dynamic subjects (high-speed video at thousands of frames per second is required for dynamic subjects as in [ WGT05 ]) and for memory-efficient relighting as hundreds of images can be required.
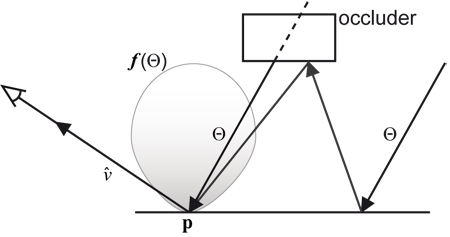
Figure 1. A reflectance function f(Θ) maps incoming
radiance directions Θ at a point p on a surface to the
resulting radiance that is reflected along the view ray
![]() towards a camera.
towards a camera.
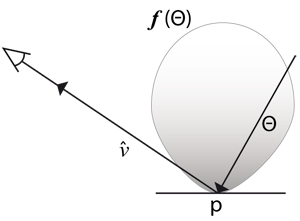
Prior works have explored efficient representations of image-based relighting datasets for rendering, generally by focusing on representations for the scene's per-pixel reflectance functions (Fig. 1) which map incoming radiance direction on the sphere to the resulting radiance (i.e. pixel color) that is reflected towards a fixed camera position.
Debevec et al. [ DHT00 ] estimated diffuse and specular albedos and normals for each pixel's reflectance function, reducing the information for each pixel from hundreds of reflectance measurements to just a few reflectance parameters. However, these parameters attempted to factor out global illumination effects, requiring these effects to be simulated later and forfeiting the elegance and realism of image-based relighting.
Malzbender et al. [ MGW01 ] fit quadratic polynomial texture maps (PTMs) to reflectance functions consisting of fifty lighting directions across the hemisphere. The PTMs greatly reduce the reflectance data to a compact, data-driven representation, and resulting renderings produce realistic and relatively smooth and diffuse renditions of the objects under varying illumination. However, the technique still requires a dense set of incident lighting directions to be recorded. Also, it restricted its consideration to lighting originating from the front hemisphere, which is a significant limitation for fully three-dimensional objects.
Ma et al. [ MHP07 ] used a computational illumination approach to modeling reflectance functions using a small number of incident lighting conditions. Using a spherical light stage and a set of four spherical gradient illumination conditions derived from the 0th- and 1st-order spherical harmonics, the technique directly measures the magnitude (albedo) and centroid (surface normal) of each pixel's reflectance function. These measurements are used to drive a Lambertian or Phong reflectance lobe to represent the reflectance function; using polarization difference imaging, the diffuse and specular components can be modeled independently. As with PTMs, the resulting renderings still encode most of the effects of global illumination. However, the lobe widths needed to be selected manually (either choosing a Lambertian lobe or a Phong specular exponent), as no reflectance lobe width information was derived from the measurements. Very recent work by Ghosh et al. [ GCP09 ] has estimated per-pixel reflectance lobe widths by adding 2nd-order spherical harmonic illumination conditions to the basis of [ MHP07 ], and also estimates anisotropic reflection parameters. However, this approach requires increasing the number of illumination conditions to at least seven even if reflections are assumed to be isotropic.
In this paper, we note that the four illumination conditions of [ MHP07 ] actually overdetermine the surface albedo (one parameter per color) and surface normal or reflected direction (two parameters per color) of each pixel's reflectance, and we show that the remaining degree of freedom holds information about the breadth of the reflectance lobe. We present two new data-driven reflectance models based on cosine lobes which can be fit analytically to measurements under the four gradient illumination conditions, one which is appropriate for opaque materials and one for semi-translucent materials. To reduce the number of lighting conditions from four to just two, we follow the suggestion of Woodham [ Woo80 ] and encode three different illumination patterns into the red, green, and blue color channels of incident illumination using a color-enabled light stage as in [ DWT02 ]. We obtain surface normal estimates through an approximate diffuse/specular separation of the reflectance, and we further enable the simulation of high-frequency cast shadows in the renderings by estimating scene geometry from the surface normal estimates. The result is an integrated technique which allows relatively detailed reflectance acquisition and simulation from an extremely small number of incident lighting conditions.
We photograph the scene inside a geodesic sphere of colored LED lights, or Light Stage, which can be programmed to produce gradient illumination as well as uniform white illumination, similar to [ DWT02 ]. The Light Stage makes use of 156 iColor MR lights from Color Kinetics corporation, which are individually controllable from a single computer via USB.
We explore two different cosine lobe reflectance
functions, which integrate easily over the uniform and
gradient illumination conditions, so that an analytic fit to
the observations is obtained. Hemispherical cosine
lobes of the form f(Θ) = k(
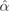 ∙ Θ)ⁿ are explored for
modeling diffuse and specular materials, but are unable to
represent materials with broader scattering such as
fur. Alternatively, spherical cosine lobes of the form
∙ Θ)ⁿ are explored for
modeling diffuse and specular materials, but are unable to
represent materials with broader scattering such as
fur. Alternatively, spherical cosine lobes of the form
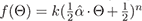 are explored for broadly
scattering materials, and are still flexible enough to offer
some representation of diffuse and specular materials. In
both models,
refers to the axis of the lobe, while k and n
are constants.
are explored for broadly
scattering materials, and are still flexible enough to offer
some representation of diffuse and specular materials. In
both models,
refers to the axis of the lobe, while k and n
are constants.
Many real-world reflectance functions are better fit by two lobes instead of one, being the so-called "diffuse" and "specular" lobes. We perform an approximate diffuse/specular separation to recover independent diffuse and specular lobes, as well as a surface normal estimate. Finally, for offline relighting we attempt to introduce high-frequency features into the reflectance functions in order to produce hard cast shadows in relit images. We first estimate the scene geometry by integrating photometric normals, and then estimate high-frequency reflectance functions based on the visibility implied by the geometry, adjusted to maintain exact reconstruction of the input photographs. These steps are described in detail in the sections that follow.
In the data acquisition stage, we make four observations
ow, ox, oy, oz
for each pixel and each color channel. The
four observed illumination conditions defined over the unit
sphere of directions Θ ∈ S2
with overall illumination
intensity L are L,
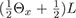 ,
,
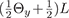 , and
, and
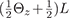 , corresponding to a full-on illumination
condition and three orthogonal linear gradient illumination
conditions. Refer to Fig. 2 for a subject photographed
under these four illumination conditions.
, corresponding to a full-on illumination
condition and three orthogonal linear gradient illumination
conditions. Refer to Fig. 2 for a subject photographed
under these four illumination conditions.

Figure 3. Top: Cat subject photographed under the full-on (A) and colored gradient (B) illumination conditions. Middle: The red, green, and blue components of the ratio of (B) to (A). Bottom: The middle row multiplied by (A). Note the resemblance to Fig. 2.

In the case of four input photographs, the four observations are trivially the input photograph pixel values. If a single colored gradient is used instead of separate x, y and z gradients, we synthesize the observations ox, oy, oz by multiplying the full-on image with each of the three color channels of the ratio image of the colored gradient image to the full-on image, motivated by [ Woo80 ]. This process is illustrated in Fig. 3. (Compare the images in Fig. 2 with the bottom row of Fig. 3.) Additionally, since the color primaries of the LEDs are not exactly the same as the color primaries of the camera sensors, we calibrate a color correction matrix prior to acquisition in order to reduce cross-talk between color channels.
It is informative to first examine the general case of the
integral of a hemispherical cosine lobe k(
∙ Θ)ⁿ times an
arbitrary linear gradient β ∙ Θ + b (with β not necessarily
unit) over the hemisphere Ω + (
) of directions on the
positive side of the axis of the lobe. The integral has the
closed form:
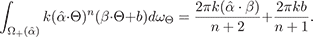 (1)
(1)
From here we trivially derive the four illumination condition observations:
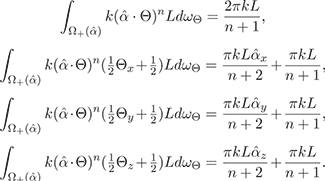
Substituting the observations ow, ox, oy, oz
corresponding
to the four lighting conditions and requiring
to be a unit
vector yields a system of five equations:
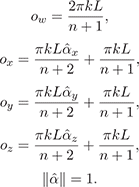
These equations admit a single closed-form solution for the cosine lobe:
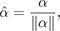 (2a)
(2a)
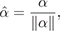 (2b)
(2b)
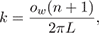 (2c)
(2c)
where α = ⟨2ox - ow, 2oy - ow, 2oz - ow⟩.
Note that the cosine lobe axis is obtained from the gradient illumination condition observations in a manner similar to the method in [ MHP07 ] for obtaining the mean spherical angle of a reflectance function. This is due to the symmetry of the cosine lobe reflectance function about its axis.
By a similar argument, a spherical cosine lobe of the
form
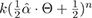 has the solution:
has the solution:
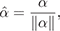 (3a)
(3a)
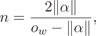 (3b)
(3b)
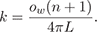 (3c)
(3c)
Figure 4. Coefficients for the cat subject under the
hemispherical cosine lobe model. Top, left to right:
x
,
y
,
z
. Bottom, left to right: k, n, zoom of n. The
value of the exponent n in the figure is scaled by 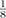 .
.

Figure 5. Relit images under a novel point-light illumination condition. The light is coming from far right. Left: hemispherical cosine lobe model. Right: spherical cosine lobe model.

We store only the coefficients of the cosine lobe reflectance model at each pixel for each color channel. Fig. 4 visualizes the coefficients for a cat subject, where the red, green, and blue channel coefficients are grouped and displayed as color images. Once the cosine lobes for each pixel and each color channel are computed, relit images can easily be synthesized for any distant illumination condition. Relit images are computed simply by sampling the cosine lobe reflectance functions for each light source in the novel illumination condition. See Fig. 5 for examples of relit images generated by this method.
The four observations under different illumination conditions in general do not contain enough information to be separated into diffuse and specular components. However, under certain assumptions about isotropy and the breadth of the diffuse and specular lobes, a separation can indeed be obtained. Notably, other than the assumptions just mentioned, this separation does not depend on any other assumptions about the shape of the lobes, so it may find applications beyond cosine lobe reflectance models.
We presume the observations o to be a sum of diffuse and specular components d and s:
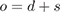
For each color channel, we consider a quantity g describing the gradient illumination observations normalized by the full-on illumination observation:
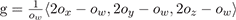
We likewise consider quantities d and s describing the normalized diffuse and specular components:
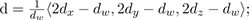
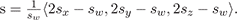
It follows that:
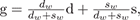
and hence g lies on the line segment
 .
.
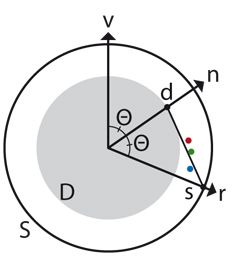
If we assume that the reflectance is isotropic, and that the diffuse component d is aligned with the surface normal n, then the vector v pointing towards the viewer and the vectors g, d and s must all lie in the same plane. Hence we define a coordinate system in the plane defined by v and (mean) g, and consider only two-dimensional vectors from here on by projecting onto this plane. On this plane, the angle Θ between v and n is equal to the angle between n and the ideal reflection vector r. Fig. 6 depicts the geometric relationships between all of these vectors. Additionally, d is the intersection of n with a circle of radius |d|, and s is the intersection of r with a circle of radius |s|.
Figure 6. On the plane defined by the view vector v
and the (mean) measured vector g: the red, green, and
blue dots are the normalized gradient vectors g of the
red, green and blue color channels; n is the surface
normal; r is the ideal reflection vector; d and s are the
normalized diffuse and specular components; and D
and S are circles of length |d| and |s|. If |d| and |s| are
known, then Θ is uniquely determined as the angle that
yields the best fit for the line segment
to the vectors
g.
If |d| and |s| are known, but n and r are unknown, we
can recover n and r (and hence d and s) by finding the
angle Θ that yields the best fit for the line segment
to
the vectors g of each color component. For example, by
Eq. ( 2) it can be shown that
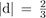 for ideal Lambertian
(diffuse) reflectance, and |s| = 1 for ideal specular (perfect
mirror) reflectance. With |d| and |s| fixed, we find just one
Θ to explain all three color channels. As the behavior of
the line segment
is non-linear, no closed form for Θ
could be obtained and hence we find it using a simple line
search.
for ideal Lambertian
(diffuse) reflectance, and |s| = 1 for ideal specular (perfect
mirror) reflectance. With |d| and |s| fixed, we find just one
Θ to explain all three color channels. As the behavior of
the line segment
is non-linear, no closed form for Θ
could be obtained and hence we find it using a simple line
search.
After Θ is found, we project the vectors g of each
color channel onto the line segment
to compute the
(per-color-channel) quantity
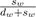 , which allows us
to recover the un-normalized diffuse and specular
components d and s. However, since the data may deviate
from our assumptions in several respects, the vectors g
may not lie exactly on the line segment
, and therefore
the reconstruction of the data using d and s may not be
exact. Therefore we let d = g -s, which has the effect of
lumping the residuals of the reconstruction into the diffuse
component, which seems acceptable as occlusion and
interreflection already pollute the diffuse component to
some degree.
, which allows us
to recover the un-normalized diffuse and specular
components d and s. However, since the data may deviate
from our assumptions in several respects, the vectors g
may not lie exactly on the line segment
, and therefore
the reconstruction of the data using d and s may not be
exact. Therefore we let d = g -s, which has the effect of
lumping the residuals of the reconstruction into the diffuse
component, which seems acceptable as occlusion and
interreflection already pollute the diffuse component to
some degree.
Finally, with the recovered diffuse and specular components d and s for each illumination condition, we fit independent diffuse cosine lobes and specular cosine lobes. By this construction, the diffuse and specular cosine lobes reconstruct the input observations exactly. See Fig. 7 for an example of diffuse/specular separation under the Lambertian / ideal specular assumption.
Figure 7. Diffuse / specular separation of the cat. Top, left to right: original full-on illumination photograph, recovered normals. Bottom, left to right: recovered diffuse component, recovered specular component.

The estimated cosine lobe reflectance function f(Θ) has only low-frequency features. Thus, while the low-frequency-illumination input photographs are reconstructed exactly, hard cast shadows cannot be synthesized for novel illumination conditions having high-frequency features. To remedy this, we estimate scene geometry by integrating the surface normals obtained in the diffuse/specular separation phase. Integration proceeds similar to [ HB86 ]. See Fig. 8 and 9 for examples of reconstructed geometry. After the scene geometry is estimated, we compute an adjusted reflectance function f'(Θ) that exhibits hard shadows cast by the geometry.
Figure 8: Reconstructed geometry from photometric normals. Top: Two views of the cat subject. Bottom: Two views of the duck subject.
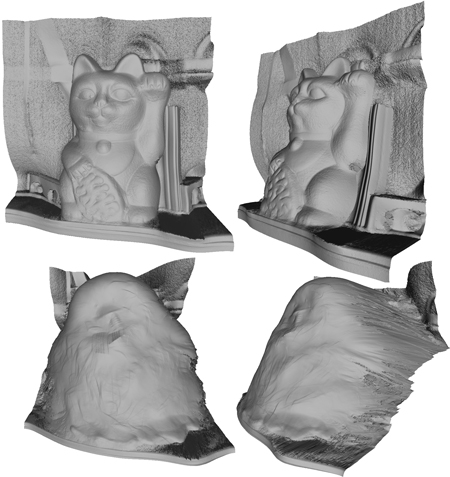
Figure 9. Reconstructed geometry for the cat subject, with normals derived from two photos instead of four.

First, consider a reflectance function f*(Θ) adjusted simply by occluding any light directions that hit scene geometry:
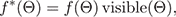 (4)
(4)
where visible(Θ) is 0 if the direction Θ is occluded by geometry or outside of the domain of f(Θ), and 1 otherwise. To reduce shadow aliasing, we allow visible(Θ) to fall off gradually from 1 to 0 near the surface of the geometry, so that a ray that just grazes the geometry will be attenuated, but still continue through the scene. In general, relighting using f*(Θ) will not reconstruct the input photographs exactly, since the low-frequency component of the reflectance function will be altered by the visibility masking. To correct this, we introduce a scaling factor c to restore the overall reflectance magnitude, and introduce a low-frequency "ambient" term ρ ∙ Θ to restore the original low-frequency component of the reflectance function:
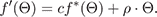 (5)
(5)
Let o* w , o* x , o* y , o* z represent synthetic observations using f*(Θ), computed by numerical integration:
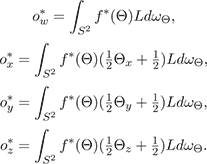
Then we correct the observations using c, ρ:
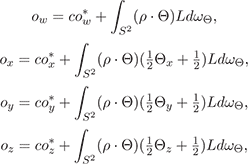
which admit one closed-form solution:
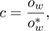 (6a)
(6a)
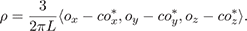 (6b)
(6b)
The plausibility of the low-frequency term ρ ∙ Θ can be justified as follows: If a ray cast in the direction Θ hits scene geometry, then the only way Θ can contribute to the resulting radiance is by indirect bounce light, as illustrated in Fig. 10. Indirect bounce light is often low-frequency in nature, so it seems appropriate to model it by a low-frequency term.
Figure 10. If a ray cast in the direction Θ hits scene geometry, then the only way Θ can contribute to the resulting radiance is by indirect bounce light.
Relighting now proceeds by sampling f'(Θ) for each light. To avoid storing the entire function f'(Θ) at each pixel, we instead store the scene geometry as a depth map, the original estimated reflectance function f(Θ) , and the correction coefficients c and ρ, and use ray casting to evaluate visible(Θ) as needed. Errors in the scene geometry, especially in the background plane, can introduce unwanted shadows into the relit images. To reduce this problem at the expense of some manual intervention, we introduce a user-supplied binary mask to prevent the background elements from occluding the foreground elements. Fig. 11 shows such a mask, and compares the results obtained with and without using the mask.
Figure 11. A user-supplied visibility mask (center) reduces unwanted shadows. Left column: Relit images under two point-light illumination conditions, no mask supplied. Right column: Mask supplied.

Refer to Fig. 12 and 13 for ground-truth comparisons with several relighting methods on the cat and duck subject, respectively. For both subjects, a linear basis relighting method is included as a baseline, which attempts to synthesize novel illumination conditions as a linear combination of the four observed gradient conditions. Note that all relighting methods tested here, including the linear basis method, reconstruct the set of input photographs exactly.
Figure 12. Relit images of cat subject under novel point light illumination conditions. A) Linear basis using four photographs. B) Hemispherical cosine lobe using two photographs. C) Hemispherical cosine lobe using four photographs. D) Diffuse and specular hemispherical cosine lobes using four photographs. E) Diffuse and specular hemispherical cosine lobes with hard cast shadows, using four photographs and user-supplied visibility mask. F) Ground truth, with inset gray balls indicating illumination direction.

Figure 13. Relit images of duck subject under novel point light illumination conditions. A) Linear basis using four photographs. B) Spherical cosine lobes using two photographs. C) Spherical cosine lobes using four photographs. D) Ground truth.

The cat subject relit with the linear basis reference method appears flat and does not convey the shape of the cat well. The two-photograph hemispherical cosine lobe method has noticeably lower quality than the four-photograph hemispherical cosine lobe method, but could be suitable for applications with limited capture budget such as video relighting. Separating the reflectance into diffuse and specular lobes significantly improves the result for the cat: the behavior of the materials under back-lighting is plausible, and specular highlights are more pronounced. Notably, the diffuse/specular separation visualized in Fig. 7 largely agrees with the materials of the actual subject. For example, the golden body of the cat is a specular material with dependency on angle, in this case a gold paint. The red collar, ears, and nose have a dominant diffuse red component with a small specular component in all channels, in this case a semi-gloss red paint. The green bib has a dominant diffuse green component, in this case a very soft diffuse green paint with a faint gloss. Most notable is the visual softness of the materials in the diffuse component. Almost without exception, the specular highlights in the original photograph are separated into the specular component, leaving a smooth diffuse component. The most visible examples include the flecks of glitter on the green bib, and the highlights in the eyes. The reconstructed geometry clearly suffers from depth ambiguities in the normal integration, but in a relighting scheme that does not attempt to alter the viewpoint, the hard cast shadows and self shadowing appear to be convincing in most cases. However, the requirement of a user-supplied visibility mask to avoid unwanted shadows in some of the lighting conditions is a notable limitation of the method, and future work should attempt to generate such masks automatically, or to improve the geometry estimate to remove the need for such masks. The duck subject relit with the linear basis reference method performs better than on the cat, but does exhibit some disturbing shadowing artifacts. The two-photograph and four-photograph spherical cosine lobe reconstructions of the duck both reproduce the scattering of the fur well in most places, and still provide a good approximation of the other materials in the scene, including the specular necktie, but some lack of self shadowing is evident. Hard cast shadows for the duck fail altogether, as shown in Fig. 14 , because the visibility masking assumption does not hold for highly scattering materials. Better self-shadowing across a wider range of materials would be an improvement sought after in future work, perhaps using a more complete estimate of visibility based on the reflectance function estimates of all pixels.
Figure 14. The visibility masking assumption does not hold for highly scattering materials such as the duck subject, resulting in an inappropriately hard shadow.

We presented a method for estimating the reflectance of a scene for the purpose of relighting, using just two to four photographs of the scene under gradient illumination. The gradient illumination photographs provide enough information to fit a cosine-lobe reflectance function, including an exponent. The cosine lobes produce plausible results for materials with reflectance dominated by a single lobe, regardless of whether the lobe results from reflection, scattering, or retro-reflection. Improved results including self-shadowing are obtained for materials having a Lambertian diffuse component and highly specular component via an approximate diffuse/specular separation. Ground truth comparisons reveal several limitations with our method, mostly stemming from violations of the assumptions made in our reflectance model. In future work we would aim to broaden the applicability of our method to a wider variety of real-world materials, to enable geometry estimation and self-shadowing for materials that fall outside of the Lambertian plus specular reflectance model.
The authors wish to thank Jay Busch and Cyrus Wilson for helping prepare the manuscript. We would also like to thank Monica Nichelson, Bill Swartout, and Randall Hill for their support and assistance with this work.
[DHT00] Acquiring the Reflectance Field of a Human Face, Proc. ACM SIGGRAPH 2000, Computer Graphics Proceedings, Annual Conference Series, 2000, pp. 145—156, isbn 1581132085.
[DWT02] A Lighting Reproduction Approach to Live-Action Compositing, ACM Transactions on Graphics, (2002), no. 3, 547—556, issn 0730-0301.
[GCP09] Estimating Specular Roughness and Anisotropy from Second Order Spherical Gradient Illumination, Computer Graphics Forum, (2009), no. 4, 1161—1170, issn 0167-7055.
[Hae92] Synthetic Lighting for Photography, 1992, www.graficaobscura.com/synth/ (Last visited September 29th, 2010).
[HB86] The variational approach to shape from shading, Computer Vision, Graphics and Image Processing, (1986), no. 2, 174—208, issn 0734-189X.
[MGW01] Polynomial Texture Maps, SIGGRAPH 01 Proceedings of the 28th annual conference on Computer graphics and interactive techniques, 2001, 519—528, isbn 1-58113-292-1.
[MHP07] Rapid Acquisition of Specular and Diffuse Normal Maps from Polarized Spherical Gradient Illumination, Rendering Techniques 2007: 18th Eurographics Symposium on Rendering, 2007, pp. 183—194.
[NSD94] Efficient Re-rendering of Naturally Illuminated Environments, Fifth Eurographics Workshop on Rendering, 1994, pp. 359—373.
[Ram06] Modeling Illumination Variation with Spherical Harmonics, Face Processing: Advanced Modeling Methods, Academic Press, 2006, 385—424, isbn 0120884526.
[RH02] Frequency Space Environment Map Rendering, ACM Transactions on Graphics, (2002), no. 3, 517—526, issn 0730-0301.
[SKS02] Precomputed Radiance Transfer for Real-Time Rendering in Dynamic, Low-Frequency Lighting Environments, ACM Transactions on Graphics, (2002), no. 3, 527—536, issn 0730-0301.
[WGT05] Performance relighting and reflectance transformation with time-multiplexed illumination, ACM Transactions on Graphics, (2005), no. 3, 756—764, issn 0730-0301.
[Woo80] Photometric Method for Determining Surface Orientation from Multiple Images, Optical Engineering, (1980), no. 1, 139—144, issn 0036-1860.
[WTL05] All-frequency interactive relighting of translucent objects with single and multiple scattering, ACM Transactions on Graphics, (2005), no. 3, 1202—1207, issn 0730-0301.
Fulltext ¶
-
 Volltext als PDF
(
Size
59.2 MB
)
Volltext als PDF
(
Size
59.2 MB
)
License ¶
Any party may pass on this Work by electronic means and make it available for download under the terms and conditions of the Digital Peer Publishing License. The text of the license may be accessed and retrieved at http://www.dipp.nrw.de/lizenzen/dppl/dppl/DPPL_v2_en_06-2004.html.
Recommended citation ¶
Graham Fyffe, and Paul Debevec, Cosine Lobe Based Relighting from Gradient Illumination Photographs. JVRB - Journal of Virtual Reality and Broadcasting, 9(2012), no. 2. (urn:nbn:de:0009-6-32649)
Please provide the exact URL and date of your last visit when citing this article.
